GPU大规模并行计算架构恰好符合深度学习的需要,通过几年的研发和积累,GPU已经成为超级计算机的重要支撑,极大的提升了机器学习的运算能力。人工智能的并行算法在过去可能需要一两年的时间才能看到结果,在GPU的强大计算能力的支持下,深度学习的算法得以突破,可以在短时间内高效能的得到数据结果
重要的消费级视频应用程序都已经使用CUDA加速或很快将会利用CUDA来加速,其中不乏Elemental Technologies公司、MotionDSP公司以及LoiLo公司的产品。
在科研界,CUDA一直受到热捧。例如,CUDA现已能够对AMBER进行加速。AMBER是一款分子动力学模拟程序,全世界在学术界与制药企业中有超过60,000名研究人员使用该程序来加速新药的探索工作。
在金融市场,Numerix以及CompatibL针对一款全新的对手风险应用程序发布了CUDA支持并取得了18倍速度提升。Numerix为近400家金融机构所广泛使用。
NVIDIA cuDNN是用于深度神经网络的GPU加速库。它强调性能、易用性和低内存开销。NVIDIA cuDNN可以集成到更高级别的机器学习框架中,如谷歌的Tensorflow、加州大学伯克利分校的流行caffe软件。简单的插入式设计可以让开发人员专注于设计和实现神经网络模型,而不是简单调整性能,同时还可以在GPU上实现高性能现代并行计算。

主要特点
· 专为NVIDIA GPU特调的,用于卷积神经网络向前和向后的卷积程序。
· 专为最新的NVIDIA GPU架构优化
· 针对4纬张量的任意维度排序,striding和次区域可以很容易集成到任何神经网络的执行中
· 对于许多其他常见布局类型(ReLU, Sigmoid, Tanh, pooling, softmax )向前和向后的路径
· 基于上下文的API,可以很容易地多线程
(3)TensorFlow神经网络算法
关于 TensorFlow
TensorFlow 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。
节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等。
TensorFlow 最初由Google大脑小组(隶属于Google机器智能研究机构)的研究员和工程师们开发出来,用于机器学习和深度神经网络方面的研究,但这个系统的通用性使其也可广泛用于其他计算领域。
核心概念:数据流图
数据流图用“结点”(nodes)和“线”(edges)的有向图来描述数学计算。
“节点” 一般用来表示施加的数学操作,但也可以表示数据输入(feed in)的起点/输出(push out)的终点,或者是读取/写入持久变量(persistent variable)的终点。
“线”表示“节点”之间的输入/输出关系。这些数据“线”可以输运“size可动态调整”的多维数据数组,即“张量”(tensor)。
张量从图中流过的直观图像是这个工具取名为“Tensorflow”的原因。一旦输入端的所有张量准备好,节点将被分配到各种计算设备完成异步并行地执行运算。
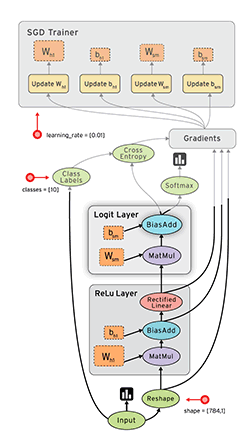

(4)教育用数据集:
经典MNIST数据集:
CIFAR10数据集:
UCI Housing数据集:
斯坦福车辆识别数据集:
猫狗大战数据集:
MovieLens百万数据集:
百度实体标注数据集:
街景门牌号识别(SVHN):
百万歌曲数据集(子集):
中文语音数据集(希尔贝壳版):
鲍鱼年龄预测:
脸部关键点识别:
IMDB情感分析数据集:
Biwi头部姿态数据集:
斯坦福狗狗数据集:
Buffy人体姿态数据集:
超分辨率重建91图:
(5)提供实验测试案例:
手势识别机器学习案例。
MINIST手写识别案例
人脸识别样例
 收藏人智科技
收藏人智科技









